We present GLEE in this work, an object-level foundation model for locating and identifying objects in images and videos. Through a unified framework, GLEEaccomplishes detection, segmentation, tracking, grounding, and identification of arbitrary objects in the open world scenario for various object perception tasks. Adopting a cohesive learning strategy, GLEE acquires knowledge from diverse data sources with varying supervision levels to formulate general object representations, excelling in zero-shot transfer to new data and tasks. Specifically, we employ an image encoder, text encoder, and visual prompter to handle multi-modal inputs, enabling to simultaneously solve various object-centric downstream tasks while maintaining state-of-the-art performance. Demonstrated through extensive training on over five million images from diverse benchmarks, GLEE exhibits remarkable versatility and improved generalization performance, efficiently tackling downstream tasks without the need for task-specific adaptation. By integrating large volumes of automatically labeled data, we further enhance its zero-shot generalization capabilities. Additionally, GLEE is capable of being integrated into Large Language Models, serving as a foundational model to provide universal object-level information for multi-modal tasks. We hope that the versatility and universality of our method will mark a significant step in the development of efficient visual foundation models for AGI systems.
1. We present GLEE, a general object-centric foundation model for images and videos. GLEE is capable of addressing a wide range of object-centric tasks simultaneously while maintaining state-of-the-art performance.
2. We develop a multi-granularity joint supervision framework and a scalable training paradigm. The unified approach of GLEE supports multi-source data and enables joint training on over five million images from various benchmarks with diverse supervision levels. This significantly facilitates the incorporation of additional manually or automatically annotated data, and simplifies the scaling of the dataset.
3. GLEE demonstrates remarkable versatility and robust zero-shot transferability across a spectrum of object-level image and video tasks. Furthermore, GLEE can provide the visual object-level information that modern LLMs currently lack, thus serving as a foundational component for enhancing other architectures or models.
The proposed GLEE consists of an image encoder, a text encoder, a visual prompter, and an object decoder, as illustrated in Figure. The text encoder processes arbitrary descriptions related to the task, including object categories, names in any form, captions about objects, and referring expressions. The visual prompter encodes user inputs such as points, bounding boxes, or scribbles during interactive segmentation into corresponding visual representations of target objects. Then they are integrated into a detector for extracting objects from images according to textual and visual input.
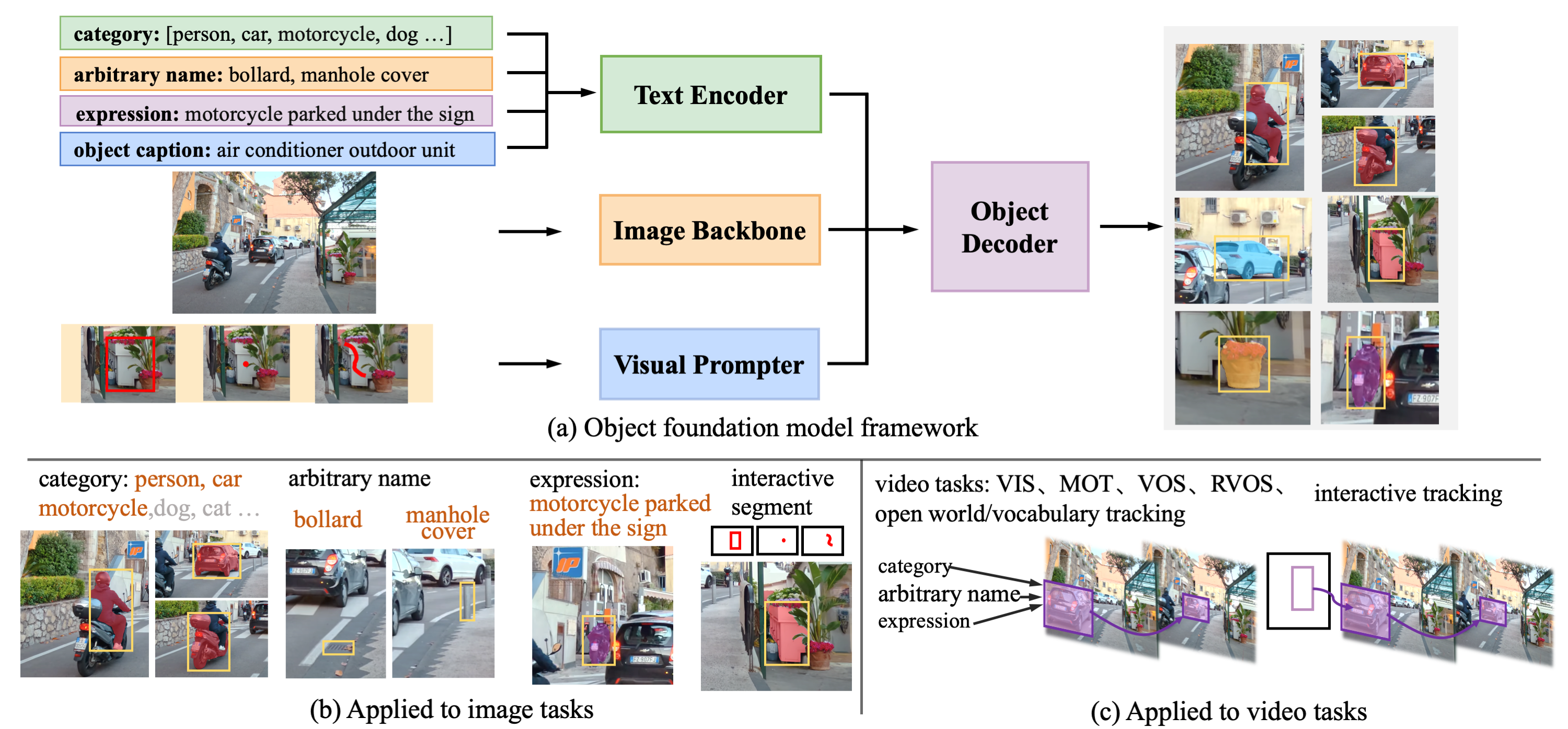
Based on the above designs, GLEE can be used to seamlessly unify a wide range of object perception tasks in images and videos, including object detection, instance segmentation, grounding, multi-target tracking (MOT), video instance segmentation (VIS), video object segmentation (VOS), interactive segmentation and tracking, and supports open-world/large-vocabulary image and video detection and segmentation tasks. A visual foundation model should be able to easily scale up the training data and achieve better generalization performance. Thanks to the unified training paradigm, the training data of GLEE can be scaled up at low cost by introducing a large amount of automatically labeled data.
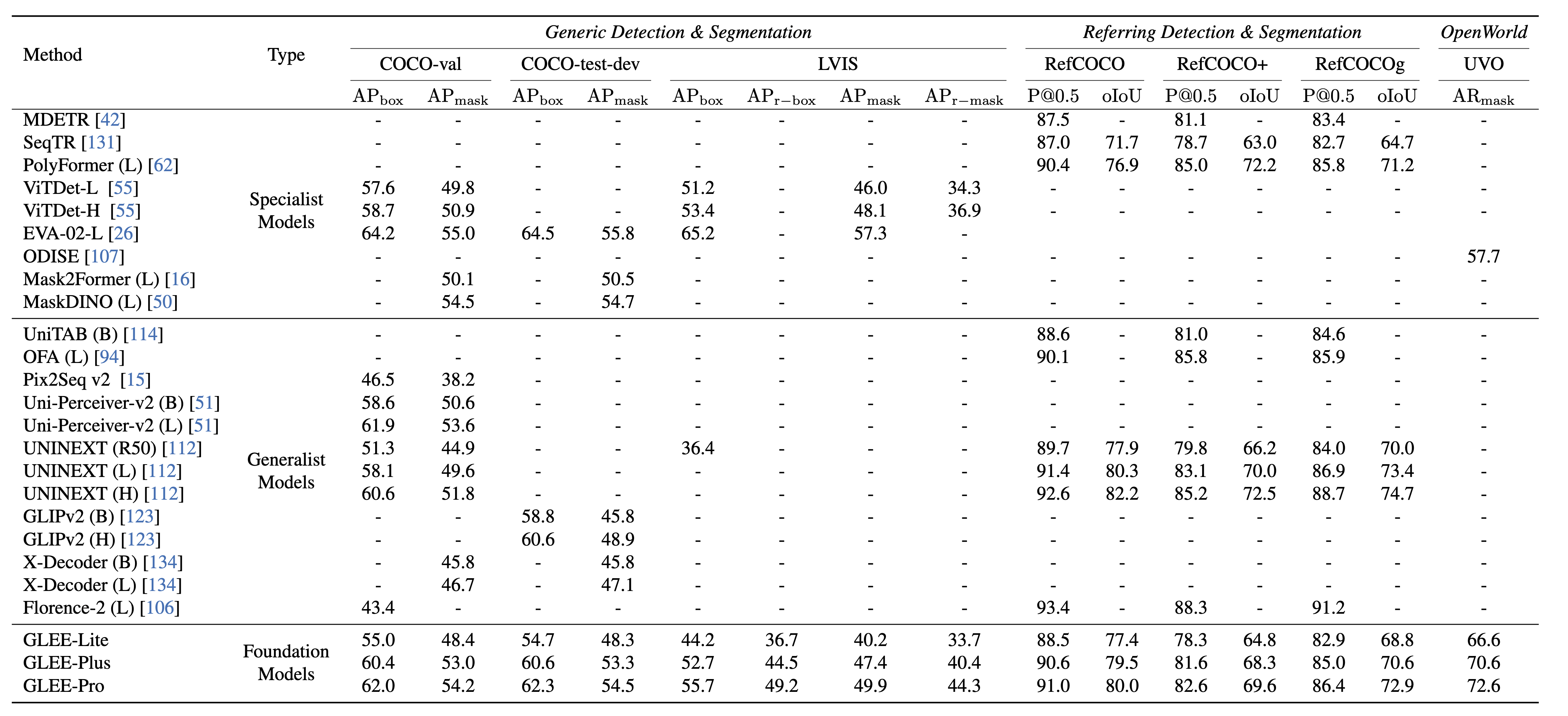
Image tasks. We demonstrate the universality and effectiveness of GLEE model as an object-level visual foundation model, directly applicable to various object-centric tasks while ensuring state-of-the-art performance without needing fine-tuning.
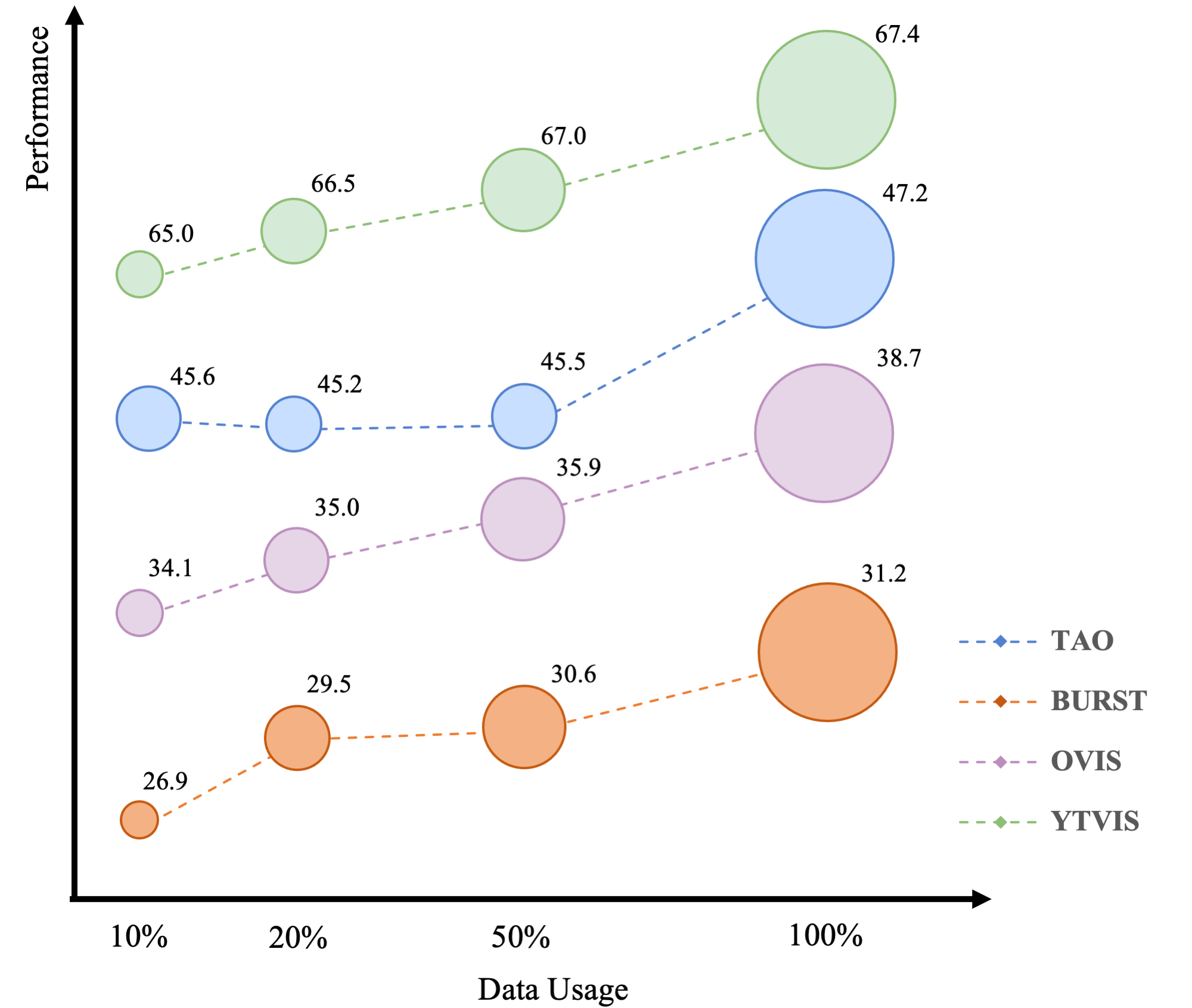
Data Scale. Train GLEE-Pro with 10%, 20%, 50%, 100% of the training data to evaluate the performance on zero-shot transfer tasks, including TAO, BURST, OVIS, and YTVIS. Increased sizes of training datasets result in enhanced zero-shot performance across diverse downstream tasks.
Serve as Foundation Model. We substituted LISA vision backbone with a frozen, pretrained GLEE-Plus and fed the object queries from GLEE into LLAVA and remove decoder of LISA. We directly dot product the output SEG tokens with GLEE feature map to generate masks. After training for the same number of steps, our modified LISA-GLEE achieved comparable results to the original version, demonstrating the versatility of representations from GLEE and its effectiveness in serving other models.
@misc{wu2023GLEE,
author= {Junfeng Wu, Yi Jiang, Qihao Liu, Zehuan Yuan, Xiang Bai, Song Bai},
title = {General Object Foundation Model for Images and Videos at Scale},
year={2023},
eprint={2312.09158},
archivePrefix={arXiv}
}